RAVEN: real-time autoregressive video extrapolation

RAVEN stands for the Real-time Autoregressive Video Extrapolation Network.
The setting we care about is real-time streaming generation, where a causal
autoregressive model has to extrapolate future chunks from previously
generated content. To make this fast we distill from a high-fidelity
bidirectional teacher into a competitive few-step model. And here the trouble
starts. The history distributions seen during training never quite match the
ones arising at inference, and that persistent gap is what constrains
generation quality over long horizons.
To see where the gap comes from, walk through how existing paradigms construct the history their causal student sees. Teacher Forcing trains with real historical chunks. The supervision is clean, but the generator never sees its own test-time history. Diffusion Forcing and CausVid perturb ground-truth prefixes with an independently sampled noise level, so the training distribution still does not match inference and the discrepancy can accumulate across autoregressive rollouts. Self Forcing finally unrolls the generator at training time, yet reuses the historical cache as detached context. The history representations still receive no end-to-end supervision from subsequent chunk losses. We call this the history supervision gap.
RAVEN closes this gap by turning training into a training-time test. We start from a self rollout of the few-step causal generator and repack that sampled trajectory into an interleaved sequence of clean historical endpoints and noisy denoising states. The clean rollout chunks supply the causal history for subsequent predictions and the noisy states from the same rollout remain the supervised denoising inputs. A single causal forward pass over this sequence then routes gradients from later chunks back through the cached history they actually depend on, without backpropagating through an entire autoregressive sampling trajectory. On top of this, a chunk-wise loss scaling gives more weight to later positions, since those condition on richer accumulated history and have to suppress error propagation. The whole design is inspired by the training-time test principle of EAGLE-3. The idea is to train the model on the context it will produce and encounter at inference. For autoregressive video diffusion that turns out to be substantially more involved, because each chunk is the endpoint of a multi-step denoising trajectory and future chunks depend on the resulting cache.
Our second contribution is CM-GRPO, short for Consistency-model Group
Relative Policy Optimization. Prior flow-model RL such as
Flow-GRPO converts the deterministic ODE
into an auxiliary SDE via Euler-Maruyama discretization, but those stochastic
transitions are absent from the ODE sampler used at inference. A consistency
sampler is different. It inherently yields stochastic Gaussian transitions
through its predicted clean endpoint. So we cast that consistency sampling
step as a conditional Gaussian transition kernel and apply group relative
policy optimization directly to this kernel. The policy interface now matches
the sampler used at inference, with no auxiliary stochastic process. The two
contributions are complementary. RAVEN aligns autoregressive training with
inference-time extrapolation and CM-GRPO defines the policy objective on the
same update rule used during generation.
We compare against recent causal video distillation baselines on VBench, including CausVid, LongLive, Rolling Forcing, Self Forcing, Reward Forcing and Causal Forcing. RAVEN surpasses every one of them across Total, Quality, Semantic and Dynamic Degree, and the largest margin lands on dynamic degree. Add CM-GRPO on top and we take the leading entry on every dimension.
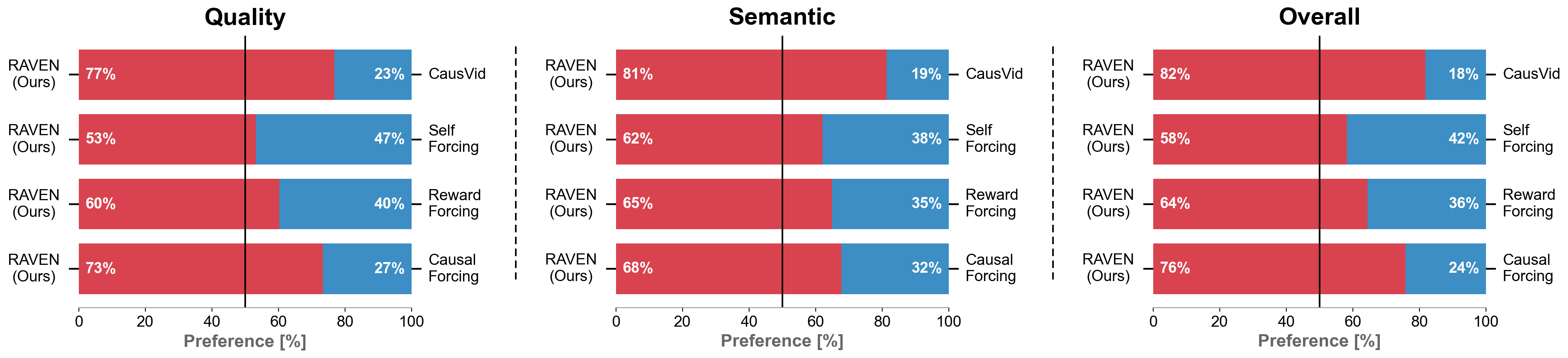
We also run a user study against the four short-video baselines, namely CausVid, Self Forcing, Reward Forcing and Causal Forcing. Across 100 long detailed prompts with 4 samples per method, RAVEN is preferred on Quality, Semantic and Overall against every one of them, with the strongest lead on Semantic.
What ties both contributions together is one principle, applied on two sides. RAVEN pulls the history representation into training, so the model learns on the context it will actually see at inference. CM-GRPO pulls the policy interface onto the inference sampler, so the RL update operates on the same kernel that produces the output. The gains we report come from closing both gaps at once.
Resources: